Humans aren't going anywhere
The Human in the loop series
This is the first post in a larger human in the loop series that takes a social libertarian stance on AI and argues why humans are relevant if not required for the wave of AI technology we experience today. Although this view contradicts many proponents of the current AI wave, I also want to lend credibility to the utility of generative AI, more specifically the transformer architecture.
In my view, the value of transformers lies more in their extension of information retrieval (i.e. search) technologies as opposed the marketed goal of building a centralized superintelligence that requires large amounts of our data and unsustainable energy demands. I believe if done correctly, this technology could set the stage to bring humans back into the loop for understanding, sharing with consent, and indexing our own precious information unlike the post-Google decades that brought us to surveillance capitalism.
The GenAI-to-AGI dichotomy
Generative artificial intelligence (GenAI) is a new wave of artificial intelligence that gained the public's attention in late 2022 when OpenAI released their ChatGPT application. GenAI uses the transformer architecture to train on large amounts of human language scraped from the internet to develop systems that mimic expected language. Despite their convincing prose, these systems lack any human-like intuition or model of the world, yet are convincing enough to fool most people that there is real understanding and critical thinking based on what is asked of them. This has split public opinion to either see humans as essential for any AI application to work properly, or sees human intelligence as soon-to-be replaced entirely by GenAI.
Artificial General Intelligence (AGI) is a theory suggesting once a computer system is given a sufficient amount of training data, it will be able to outperform human's in nearly every task and update its own understanding, or world model, without the need for human intervention. Unfortunately the GenAI-to-AGI debate has followed suit to our tribal political environment, causing many to support or oppose the use and development of GenAI altogether.
 Gary Marcus, a psychologist at NYU and early skeptic of the utility of today's LLM-based AI systems, and OpenAI CEO Sam Altman in 2023. Photo by: Andrew Caballero-Reynolds/AFP—Getty Images
Gary Marcus, a psychologist at NYU and early skeptic of the utility of today's LLM-based AI systems, and OpenAI CEO Sam Altman in 2023. Photo by: Andrew Caballero-Reynolds/AFP—Getty Images
AGI skeptics against GenAI investment correctly see current implementations like ChatGPT as exploitative of the humans who created both public and private work without consent, energy hungry and unsustainable, failing to create real value, creating real job loss, and causing mental health problems for its users.
Those who believe GenAI will achieve AGI, tend to focus on theoretical benefits, often see these downsides as inevitable and temporary precursors to AIs pending value towards global human progress. This group is made up of technooptimists who generally lack of accessible education on how GenAI works, are CEOs investing in AI due to groupthink consensus, or are otherwise often profiting off of the AGI narrative in some way or another.
There is of course, a group of technophobic folks that also believes GenAI will become AGI but fall into the anti-GenAI category from fear the technology will evolve itself to wipe out humanity. I won't lie, there was a week where I felt this way before I educated myself on how the parlor trick worked. We can add this diminishing group to the anti-GenAI group. Let's then focus on the group who allegedly believes GenAI still could become AGI and view it as a positive for humanity.
In an IBM study that questioned 2000 CEOs, two-thirds of the participants acknowledge they are taking a risk on AI and don't have a clear understanding of how it would value their company. A little over third of the CEOs believe, “it’s better to be 'fast and wrong' than 'right and slow' when it comes to technology adoption.” An even smaller group among the GenAI-to-AGI crowd are the techno-elitists who have a vested stake in selling the notion of AGI as this incentivizes large and centralized AI systems become ubiquitous to build monopoly in a domain with few regulations or public understanding. Further, the AGI narrative has spurred on nationalist technology race between the United States, China, and other countries adding a sense of urgency and impetus to ignore the impact of the scaling war on the climate and energy needs of local populations.
Like many in the AI community, I believe generative language models provide value and should be researched — but building AGI superintelligence as the north star with unrestricted resource consumption is where I believe we must draw the line. This is actually where a lot of nuance between the two extreme viewpoints lives, and it's exactly where the conversation needs to be today. What is important to understand that GenAI is not synonymous with developing superintelligence, displacing humans from jobs, hoarding energy resources from communities, and enabling capitalist to profiteer off our personal information. Despite what either side believes, businesses and investors are running low on patience and there would need to be a drastic boost in performance of the next large model for Silicon Valley to continue this experiment.
The business use case for artificial intelligence
If you look at the economy and the language used by company leadership when describing their investment in AI, the sentiment becomes clear. “65% (of CEOs) say their organization will use automation to address future skill gaps”, which signals their intent to use GenAI to cut their staff budget. Yet, the MIT NANDA project just released a report that found that, “despite $30–40 billion in enterprise investment into GenAI...95% of organizations are getting zero return.”
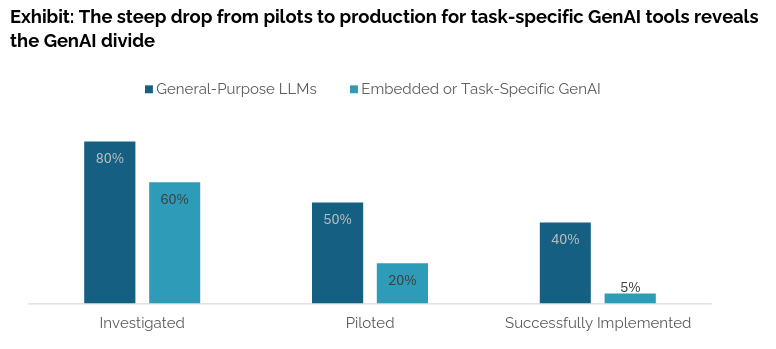
The report continues to point out;
the primary factor keeping organizations on the wrong side of the GenAI Divide is the learning gap, tools that don't learn, integrate poorly, or match workflows. Users prefer ChatGPT for simple tasks, but abandon it for mission-critical work due to its lack of memory. What's missing is systems that adapt, remember, and evolve, capabilities that define the difference between the two sides of the divide.
What I found most striking about this report is its focus on value to mission-critical workflows that rely on carbon-based employees with domain experience to keep it running. The receipts that AI will actually replace us are not showing up due to the lack of leadership to guide current staff to retrofit AI into production workflows to replace their human intuition. Ironically, this report mentions that most employees showed higher value from simpler interface like ChatGPT over inflexible domain-specific tooling that wasn't able to adapt to a company's specific needs. That said, simpler interfaces were only useful for the most basic tasks as opposed to complex or domain-specific work.

The 5% of pilots that were successful in domain-specific workloads, “focus on narrow but high-value use cases, integrate deeply into workflows, and scale through continuous learning rather than broad feature sets. Domain fluency and workflow integration matter more than flashy UX.” This both indicates that there is clearly value to this technology, but the ROI is evident only in narrow AI use cases as opposed to general use cases. Without true ROI to businesses, the centralized super-intelligent system will no longer justify the cost required to fund the costly and energy-inefficient scale of larger and larger models.
Where the buck stops
I would like to challenge three sentiments characterized by the current AI companies that are essential to the hype and high valuation:
- Language models must be “large” in their training data in order to achieve the value companies see with GenAI today.
- Language models must be proprietary and centralized to perform the best in comparison to open models.
- Language models do not need humans to evolve their understanding of the world.
Does infinite scale mean infinitely better performance?
Cal Newport recounted in his recent New Yorker article, that the original premise set by an OpenAI paper from 2020 argued that language models would likely perform much better at virtually any task if you trained language models on larger data sets. The release of GPT-3 provided compelling evidence as it used ten times more data and saw drastically improved performance over the prior GPT-2 model. This evidence was sufficient enough for venture capital investors to further testing and had a rather convenient narrative to centralize and profit off the technology.
If OpenAI's theory was correct, they could build a system with the potential to outperform humans on any task, and was only attainable with more money, more computing power, and more data. The continued success of OpenAI's larger GPT-4 model boosted the momentum of this belief, and had investors throwing money at multiple companies in hopes they would invest in the one that made it to AGI first.
This was only to be followed by years of incremental releases from OpenAI's competitors on bigger models that barely performed better and OpenAI's continuous delays of the GPT-5 release. The AI industry began expressing doubt if scaling would consistently provide exponentially growing results. After two and a half years since the GPT-4 release, the unimpressive release of GPT-5 left the question on everyone's mind, “Was GPT-4 the peak size and performance for transformer-based models?”
This question causes a great deal of tension today as this larger-means-better approach starts to unfold. The entire viability of Nvidia's surge in valuation lies at the heart of the truth of this scaling power law. If models don't require increasingly larger datasets to perform better, then Nvidia's sales will stagnate once companies have a sufficient amount of GPUs to train and fine-tune existing open models. It's not that Nvidia won't sell a lot of GPUs in the near future, it's that the number has a clear finite bound. This can be further constrained as open models provide a clear path to build custom models without the entry fee of starting from scratch.
Open models prove size isn't always what matters
Open source has become part of the strategic landscape and how companies like Meta diminish OpenAI's advantage by growing a community around an open alternative as they did with the LLaMa model. Open language models come in all domains and sizes and are widely available on platforms like Kaggle and HuggingFace. Some models obfuscate model training and release model weights for use and limited reuse, while other models open their entire training sets and publish their methods to communities like OpenML or MLCommons. A study from late 2024 compared the performance of open models like LLama 2, Phi 2, and Mistral OpenOrca against OpenAI's GPT-3.5 and GPT-4, which concluded:
Open-source models, while showing slightly lower scores in terms of precision and speed, offer an interesting alternative due to their deployment flexibility. For example, Mistral-7b-OpenOrca achieved an 83% exact match and a ROUGE-2 score of 80%, while LLaMA-2 showed a 76% exact match, proving their competitiveness in controlled and secure environments. These open-source models, with their optimized attention mechanisms and adjusted quantization configurations, show that they can compete with proprietary models while allowing companies to customize the models according to their specific needs. These models represent viable and cost-effective solutions for sectors where data privacy and the ability to deploy on private infrastructures are essential.
Open models make it possible for more companies to outperform proprietary models with the use of retrieval augmentation or fine-tuning methods. This begged the question for companies who value cost-efficiency, How well do transformer models work with fine-tuned smaller models and other attention tuning like retrieval augmentation?
Fine-tuned small language models (SLMs) have also begun to outperform large language models from traditional tasks like text classification, to domain-specific edge models and coding tasks with lower operating costs and higher ROI. This fine-tuning and RAG optimization doesn't come for free, but it has more compounding of benefits for users and avoids lock-in to proprietary models. Of the 5% of domain-specific workloads that succeeded in the MIT study, the collaborations between domain-specialists and AI engineers provided substantial benefit through making the mechanisms of generative AI more transparent to knowledge workers, increasing their trust in these tools and providing more confidence to use them to automate other workflows. Domain specialists can then tweak updates of shifting institutional knowledge to a company's custom model while bringing more efficient workloads into the scaffold of mission-critical tasks.
It's hard to say that there will never be a case for large models, perhaps everyone will still want ChatGPT but cheaper and less AGI focused. If more research is placed into improving the performance of small language models towards the optimal performance of GPT-4. Then perhaps this is still a valid, albeit way smaller, use case for these general models that could be offered as a service to more and more companies. This does put a nail in the coffin of mindless scaling as a means to generate higher-value for consumers.
Will SLMs and open models kill centralized or proprietary models?
The growing research using open models substantially reduced the overall necessity and therefore value of a centralized platform. If training does not require substantial investment in a large data center, there would be more long-term value for companies with enough use cases to invest in developing internal or use existing open tools to create and run domain-specific models. As I pointed out in Your Own Private AI, any consumer these days can run open models locally and use RAG to train on their own information. This makes it nearly impossible for a single AI company like OpenAI to become the next Google monopoly in information networks.
In contrast, this opens up room for a new market of smaller proprietary and domain-specific AI in tools. This may look similar to the current proliferation of LLM wrapper companies, with the difference of them taking the time to think through and develop their own foundational models to address specific needs. The models won't necessarily need to be large, but rather, work incredibly well within their domain. The only centralization of knowledge would exist for that domain, but it is no longer trying to get data from every corner of the planet to solve all problems. This ends up looking like a slightly more generalized version of narrow or traditional AI tooling. This tooling may be so insignificant to any domain, that the application may not even be branded as an AI tool, but rather serving some features of an application much like Markov Chains give us autocorrect on our phones.
What about the job market?

As the narrative that all human value can be produced better and faster by a centralized superintelligence fades into the next AI winter, we are then left with an insecure feeling that AGI didn't happen this time, but what about the next? Because GenAI was such a convincing parlor trick, it spurred on a lot of conversations and new research across experts in anthropology, neuroscience, computer science, and artificial intelligence. It became very important for us to understand how we humans think, learn, and most importantly, what we take for granted about our organic and specifically human cognition.
I personally took solace in learning that large language models emulate language, but they don't model a world view, nor are they guided by biological stimulus like emotions that factor into their learning. I'm not saying that computers couldn't outpace us in some ways, but drove me to question the vast complexity of our own experience that we rarely practice metacognition as we are always thinking much like we always breathe and have a heartbeat. What also becomes clear when looking at this is how early research is on understanding the connection between our thoughts and the biological matter we've evolved over millennia. I'd like to share one aspect of human cognition we do understand that already falls outside of what is modeled by a language model, which is, the human nervous system's role in conscious thought.
Language models can't emulate human cognition

I recently learned about the Enteric Nervous System (ENS), our “second brain”, which is a mesh-like system of neurons that controls our gastrointestinal track. It can control digestive function entirely on its own without signals from our brain or the central nervous system. It is responsible for 90% of the serotonin and 50% of the dopamine generated in our body which has a large effect on your emotional state. It is why we use the language of “gut” feelings that describe our intuition that guides our decision making. It also sends signals that make us cranky and contributes to worse decision-making when we are hungry. Because humans aren't just brains with fingers and we have an entire body that dictate how we think and learn, we must consider the many complex systems of human anatomy factor into our experience when making a choice. This is just one of many things that make human thinking distinct from AI, and why we need to avoid comparing language emulation models to human thought.
If that weren't enough, there is a much more complex way our behaviors are affected by our environment, culture, social interactions, and the information we consume. When we see AI generate false information with no model to verify it against (i.e. “hallucinates”), it is clear that AI is only working in limited language or sensory dimensions such as image and video to generate something that is plausible or possible, but not likely correct. There's a lot of great reading in AI papers from the 2000s that aimed to create models like Distributed Cognition not even to build an AI model around it, but simply to create a vocabulary framework around complex cognition seen in animals to clarify different taxonomies of the type of cognition being emulated and which weren't. It's a starch reminder about how anthropomorphism and confirmation bias can cause us to be reductive of the complex mechanisms of our cognition. Although it's still possible that one day we will build AGI that may or may not think like a human, it most definitely won't be agents or language models. I believe most, if not, all jobs are safe from being replaced from language models.
In the post LLM hype, my anticipation will be a rise in the job market. Transformer-based model research will live on in AI academia and in business, and we'll see an explosion in developments around open training and open data sets. There will be a larger focus on developing domain-specific smaller models with fine-tuning. There will also be a large interest in embedded AI for IOT devices and lower energy consumption. This type of AI economy makes knowledge of every human valuable. It will take time and will require consent if we do this right.
Companies should still invest in AI, but gradually and following the techniques by the few successful companies that have had success. This will involve bringing back the domain experts and human resources AI suggested we could replace, and instead train them on how to effectively use AI in their workflow. As employee knowledge becomes important, companies must prioritize proper documentation and knowledge work. If leaders focus on proper incentives to capture workflows across teams through internal wikis, software logic mapping and validation, ops reports, meeting summaries, etc... GenAI has a lot of potential to lower the burden of time-consuming communication gaps and can provide a lot of information for experts to share knowledge with newcomers and remain productive within their role. This all comes down to telling the right stories around how we enable individuals to do their best work and their unique experiences and talents to shape the larger company organism into a more efficient being.
GenAI and Search
The single greatest pervasive and most influential information technology we know today is search, specifically Google's search initially powered by PageRank. Though general open source search engines like Solr, Lucene, Elasticsearch, meta search engines like SearXNG, and more modern vector and search hybrids like meilisearch, these only provide the mechanisms of how search works, but are missing the gargantuan amount of data that Google possesses through its search monopoly, data-collecting products, adware metrics, and its highly adopted web browser that feed into both providing context for search. The slow coercive shift of society granting Google its incredible influence over how humans around the globe mentally model and obtain knowledge that form our world views also shaped the way in which netizen's structure their information to be found.
Much of the GenAI data was procured without consent from the large troves of publicly available data. This ranged from troves of information scraped off of forum sites like, Reddit and StackOverlow, to small sites from individual blogs. All of these were used to feed the large data needs of the LLMs. As we sit here in the aftermath of this technology, I think it's incredibly important that we reflect on the importance of how we structure our information as a internet society. There is clearly power in the conversations we have and information we produce. It's important that the exploitative practices of companies like OpenAI and Google drive us towards safeguarding personal information, while ensuring our intellectual assets remain available to the public. We should continue building the consensual information sharing of information to benefit everyone, while safeguarding personal information from private benefactors that can leave the public vulnerable in the current political climate.
Many in open source have started developing open alternatives that enable us to create and use our information on our own terms. Social media alternatives have grown through Fediverse technologies, such as Mastadon and Pixelfed. There are also user-driven search systems such as USENET that enable users to curate our own search indexes and share it with others. This could both build information netowrks that would create an information economy that expands our existing peer-to-peer blog funding economies. Rather, you would be funded by curating valuable information in your expertise. However, today's average netizen would consider a system like USENET complex and unusable as it was created before social media and personal phones shapes how users find information.
Much of the current challenge poised to open designers and developers is to match current search mental models with those of a new system, that would also link across sites through semantic web standards. For those who understand how to build these economies can make some early examples themselves and train future generations of individuals and corporations on how to manage and profit off their own open digital gardens. I believe democratizing the ownership of information flow occurs on the internet will break up information bubbles and enable us to share the information we want and maintain our privacy where we want.
Nobody can do that alone, but it is possible if we start to pull our resources together and build something that has the distribution of USENET, the UX search model of Google, the interoperability of the semantic web, and the ability for folks to work on a repository of documents like Wikipedia, but many small wikis that can reference eachother. With proper design and consent mechanisms, humans will want to collectively curate the valuable information in our own heads into shared value for globally interconnected local economies.
We'll dive more into some of these fundamentals in the rest of this series. The next post will dive into the internals of search technology and its relevance to GenAI.