A gentle introduction to the Hive connector
TL;DR: The Hive connector is what you use in Trino for reading data from object storage that is organized according to the rules laid out by Hive, without using the Hive runtime code.
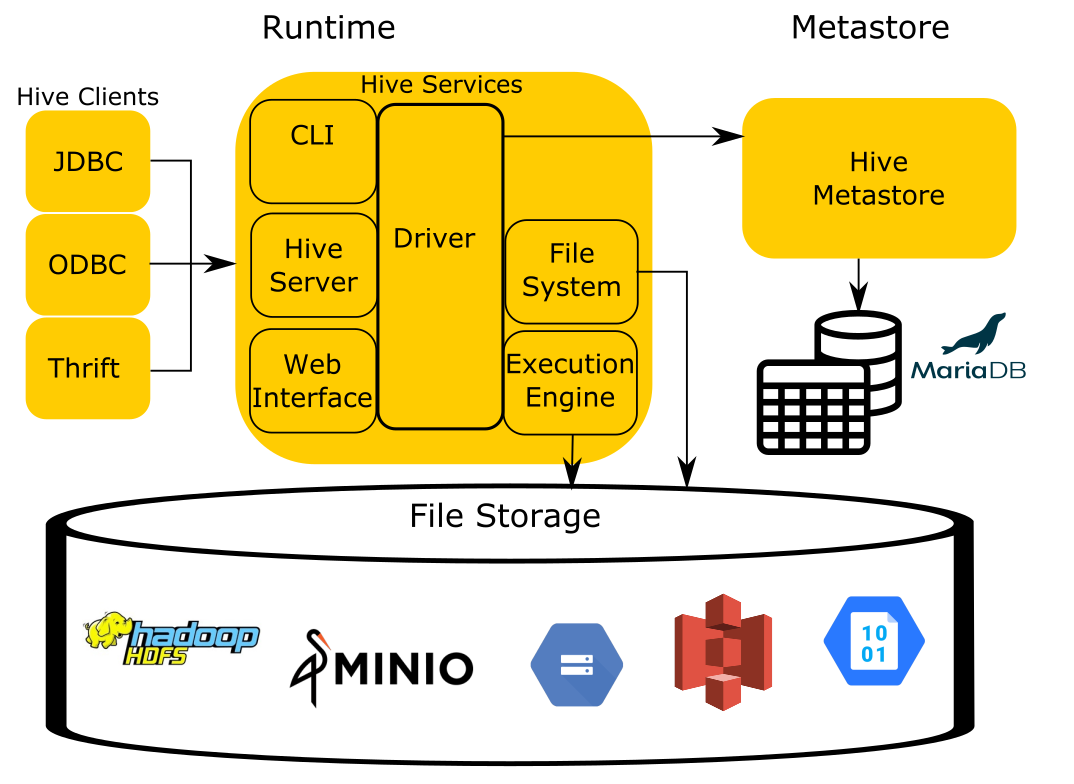
TL;DR: The Hive connector is what you use in Trino for reading data from object storage that is organized according to the rules laid out by Hive, without using the Hive runtime code.