This is the first post in a larger human in the loop series that takes a social libertarian stance on AI and argues why humans are relevant if not required for the wave of AI technology we experience today. Although this view contradicts many proponents of the current AI wave, I also want to lend credibility to the utility of generative AI, more specifically the transformer architecture.
In my view, the value of transformers lies more in their extension of information retrieval (i.e. search) technologies as opposed the marketed goal of building a centralized superintelligence that requires large amounts of our data and unsustainable energy demands. I believe if done correctly, this technology could set the stage to bring humans back into the loop for understanding, sharing with consent, and indexing our own precious information unlike the post-Google decades that brought us to surveillance capitalism.
I've had a bunch of conversations with family, friends, and folks who avoid tech until it's necessary about the latest wave of artificial intelligence (AI) craze. A lot of these folks are curious to use AI, but are concerned about privacy or receiving biased views and misinformation. Many technologists have limited this exposure using locally running AI models which avoids sharing personal information to platforms and enables you to choose a model that has more public validation of the data it trains on and therefore why it may have a stance on a particular topic.
I realized how most blog posts on how to run local AI are written by technologists for technologists and everyone else is beholden to ChatGPT and the like. I myself have been quite excited about the potential for AI, but as a socialist who has worked in the Big Data industry and seen how information is being used against the average citizen, I want to help everyone in learning how to take ownership of your information without avoiding participating in this fun and valuable tech.
TL;DR: Contributing to open source can be frustrating as the consensus needed for code to align to the project vision is often out of scope for many companies. This post dives deep into the obstacles and wins of two contributors from different companies working together to add the same proprietary connector. It's both inspiring and carries many lessons to bring along as you venture into open source to gain the pearls and avoid the perils.
We’re seeing open source usher in a challenge to the economic model where the success metric is increasing the commonwealth of economic capital. This acceleration comes from playing positive-sum games with friends online and avoiding limiting a community to a vision that only benefits a small number of corporations or individuals. It’s hard to imagine how to embed such frameworks within our current zero-sum winner-takes-all economic system.
TL;DR: I believe Apache Iceberg won the table format wars, not because of a feature race, but primarily because of the open Iceberg spec. There are somefeatures only available in Iceberg due to the breaking of compatibility with Hive, which was also a contributing factor to the adoption of the implementation.
Learn how to quickly join data across multiple sources
If you haven’t heard of Trino before, it is a query engine that speaks the language of many genres of databases. As such, Trino is commonly used to provide fast ad-hoc queries across heterogeneous data sources. Trino’s initial use case was built around replacing the Hive runtime engine to allow for faster querying of Big Data warehouses and data lakes. This may be the first time you have heard of Trino, but you’ve likely heard of the project from which it was “forklifted”, Presto. If you want to learn more about why the creators of Presto now work on Trino (formerly PrestoSQL) you can read the renaming blog that they produced earlier this year. Before you commit too much to this blog, I’d like to let you know why you should even care about Trino.
So far, this series has covered some very interesting user level concepts of the Iceberg model, and how you can take advantage of them using the Trino query engine. This blog post dives into some implementation details of Iceberg by dissecting some files that result from various operations carried out using Trino. To dissect you must use some surgical instrumentation, namely Trino, Avro tools, the MinIO client tool and Iceberg’s core library. It’s useful to dissect how these files work, not only to help understand how Iceberg works, but also to aid in troubleshooting issues, should you have any issues during ingestion or querying of your Iceberg table. I like to think of this type of debugging much like a fun game of operation, and you’re looking to see what causes the red errors to fly by on your screen.
In the last two blog posts, we’ve covered a lot of cool feature improvements of Iceberg over the Hive model. I recommend you take a look at those if you haven’t yet. We introduced concepts and issues that table formats address. This blog closes up the overview of Iceberg features by discussing the concurrency model Iceberg uses to ensure data integrity, how to use snapshots via Trino, and the Iceberg Specification.
The first post covered how Iceberg is a table format and not a file format It demonstrated the benefits of hidden partitioning in Iceberg in contrast to exposed partitioning in Hive. There really is no such thing as “exposed partitioning.” I just thought that sounded better than not-hidden partitioning. If any of that wasn’t clear, I recommend either that you stop reading now, or go back to the first post before starting this one. This post discusses evolution. No, the post isn’t covering Darwinian nor Pokémon evolution, but in-place table evolution!
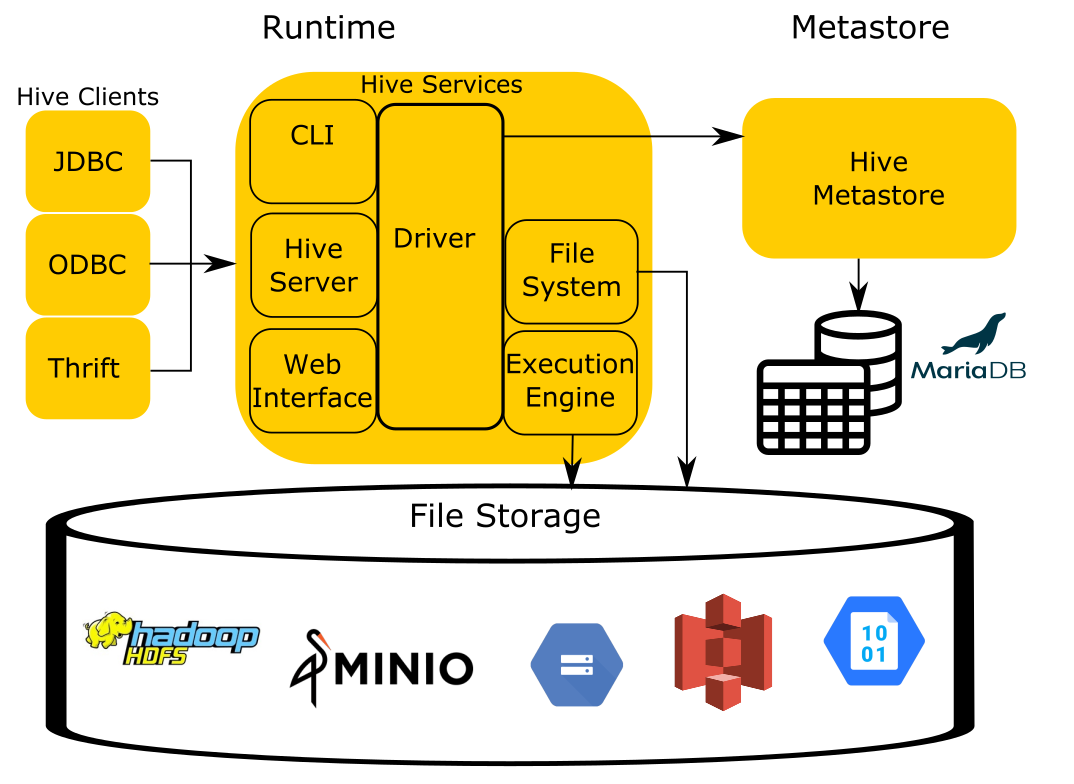
Back in the Gentle introduction to the Hive connector blog post, I discussed a commonly misunderstood architecture and uses of the Trino Hive connector. In short, while some may think the name indicates Trino makes a call to a running Hive instance, the Hive connector does not use the Hive runtime to answer queries. Instead, the connector is named Hive connector because it relies on Hive conventions and implementation details from the Hadoop ecosystem – the invisible Hive specification.
TL;DR: The Hive connector is what you use in Trino for reading data from object storage that is organized according to the rules laid out by Hive, without using the Hive runtime code.