TL;DR: I believe Apache Iceberg won the table format wars, not because of a feature race, but primarily because of the open Iceberg spec. There are somefeatures only available in Iceberg due to the breaking of compatibility with Hive, which was also a contributing factor to the adoption of the implementation.
Learn how to quickly join data across multiple sources
If you haven’t heard of Trino before, it is a query engine that speaks the language of many genres of databases. As such, Trino is commonly used to provide fast ad-hoc queries across heterogeneous data sources. Trino’s initial use case was built around replacing the Hive runtime engine to allow for faster querying of Big Data warehouses and data lakes. This may be the first time you have heard of Trino, but you’ve likely heard of the project from which it was “forklifted”, Presto. If you want to learn more about why the creators of Presto now work on Trino (formerly PrestoSQL) you can read the renaming blog that they produced earlier this year. Before you commit too much to this blog, I’d like to let you know why you should even care about Trino.
So far, this series has covered some very interesting user level concepts of the Iceberg model, and how you can take advantage of them using the Trino query engine. This blog post dives into some implementation details of Iceberg by dissecting some files that result from various operations carried out using Trino. To dissect you must use some surgical instrumentation, namely Trino, Avro tools, the MinIO client tool and Iceberg’s core library. It’s useful to dissect how these files work, not only to help understand how Iceberg works, but also to aid in troubleshooting issues, should you have any issues during ingestion or querying of your Iceberg table. I like to think of this type of debugging much like a fun game of operation, and you’re looking to see what causes the red errors to fly by on your screen.
In the last two blog posts, we’ve covered a lot of cool feature improvements of Iceberg over the Hive model. I recommend you take a look at those if you haven’t yet. We introduced concepts and issues that table formats address. This blog closes up the overview of Iceberg features by discussing the concurrency model Iceberg uses to ensure data integrity, how to use snapshots via Trino, and the Iceberg Specification.
The first post covered how Iceberg is a table format and not a file format It demonstrated the benefits of hidden partitioning in Iceberg in contrast to exposed partitioning in Hive. There really is no such thing as “exposed partitioning.” I just thought that sounded better than not-hidden partitioning. If any of that wasn’t clear, I recommend either that you stop reading now, or go back to the first post before starting this one. This post discusses evolution. No, the post isn’t covering Darwinian nor Pokémon evolution, but in-place table evolution!
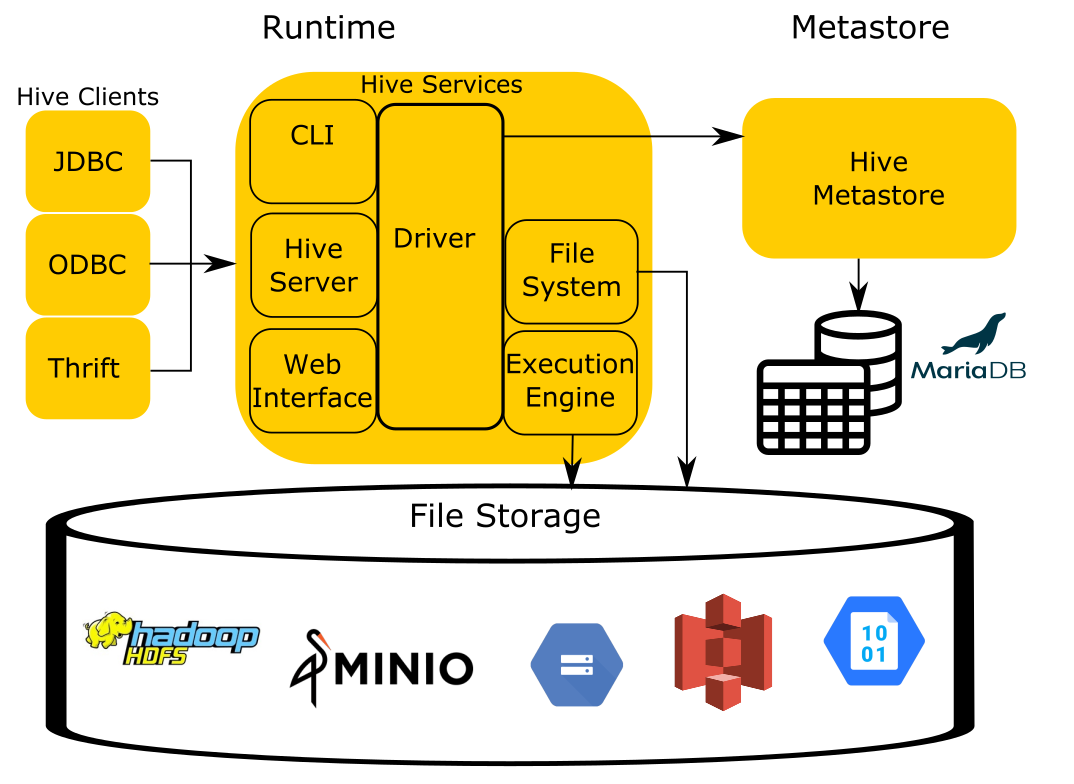
Back in the Gentle introduction to the Hive connector blog post, I discussed a commonly misunderstood architecture and uses of the Trino Hive connector. In short, while some may think the name indicates Trino makes a call to a running Hive instance, the Hive connector does not use the Hive runtime to answer queries. Instead, the connector is named Hive connector because it relies on Hive conventions and implementation details from the Hadoop ecosystem – the invisible Hive specification.
TL;DR: The Hive connector is what you use in Trino for reading data from object storage that is organized according to the rules laid out by Hive, without using the Hive runtime code.
There’s something I have to get off my chest. If you really need to, just read the TLDR and listen to the Justin Bieber parody posted below. If you’re confused by the lingo, the rest of the post will fill in any gaps.
TL;DR: Benchmarketing, the practice of using benchmarks for marketing, is bad. Consumers should run their own benchmarks and ideally open-source them instead of relying on an internal and biased report.